
LLM stands for large language models, like OpenAI’s ChatGPT and Google’s Bard. LLMs are, almost always, a very big neural network that takes natural language texts as input, and outputs some other natural language texts.
But how large is large? The “largeness” of a model is usually measured by the number of parameters it contains. And the largest known model (as of Feb 2023) is Google’s PaLM with 540 billion parameters.
Pre-LLM
Rome wasn’t built in a day, neither is LLMs. There has been quite a development process for LLMs, starting from Word2vec.
Word2vec
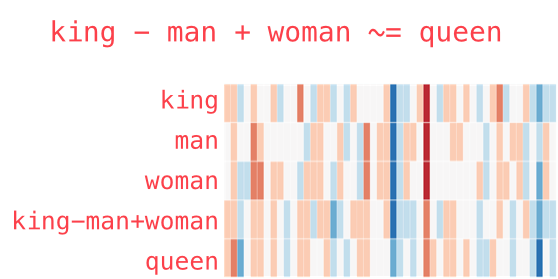
Many ML practitioners have used word2vec (word-to-vector) before. First proposed in 2013, word2vec can transform each word in the input dataset to a vector (a list of float numbers), therefore converting texts into numbers. More amazingly, the converted vectors can actually capture the semantic relevance of the words. The most famous example to illustrate is “king” – “man” + “woman” ~= “queen” (source).
LSTM network & Transformer
LSTM stands for long short-term memory. As the name suggests, this neural network introduced something called “memory units”, which is designed to learn long-term dependencies, especially in sequence prediction problems.
Based on LSTM, a major breakthrough was made in 2017, when Google Brain released a paper called Attention Is All You Need. This paper established the foundation of LLM as it introduced “Transformer”, a new neural network architecture based on “attention” (hence the name “Attention is All You Need”). The key point of this new concept is that the transformer was a sequence to sequence network (both input and the output are sequences, e.g., a sentence or document).
OpenAI and ChatGPT
OpenAI is the name of the company that invented ChatGPT.
OpenAI was at its infant stage as Transformer was introduced to the world. Inspired by Transformer, OpenAI came out with their own model that explored the potential of Generative Pre-Training method, which later developed into the famous ChatGPT.
The significance of this method is that it demonstrated the good performance of pretraining a large transformer based model on a large volume of text and then fine tuning the model on a more specific problem in a smaller domain.
And as technology progresses, OpenAI released their largest LLM model (GPT-3) in June, 2020 with 175 billion parameters. And as rumor has it that the next gen GPT-4, which will be released somewhere in the first quarter of 2023, will have more than 100 trillion parameters (this is probably false).
Hallucination?
ChatGPT users may have noticed that the AI sometimes gives a wrong answer very confidently. This is called hallucination (or artificial hallucination).
As LLMs like ChatGPT are designed to predict next work in a sequence while not checking if the output is true or not, this can cause the LLMs to make things up frequently. Thus, the output of LLMs can seem very plausible but totally made-up.
One thing to note is that hallucination is not a ChatGPT only problem, and there are currently no good solutions to this problem.
LLM’s Real World Applications
Chatbots, of course, is LLM’s first real world application. But what else? As LLMs are language models based on text, their applications are naturally highly relevant to texts. To just name a few,
- Chatbots and Virtual Assistants: Large language models can be used to power chatbots and virtual assistants, providing human-like interactions and personalized responses to users.
- Translation: Large language models can be used to translate text from one language to another, making communication easier across language barriers.
- Content Creation: Large language models can generate high-quality, human-like text for a variety of purposes, such as marketing copy, news articles, and social media posts.
- Search Engines: Large language models can be used to improve the accuracy of search results, providing more relevant and helpful information to users.
- Customer Service: Large language models can be used to assist customer service teams by providing automated responses to common queries and directing customers to the right resources.
- Healthcare: Large language models can be used to analyze patient data and provide personalized medical recommendations and treatments.
- Natural Language Processing (NLP): Large language models can be used to improve NLP tasks, such as sentiment analysis, named entity recognition, and text classification.
- Education: Large language models can be used to provide personalized learning experiences, recommend educational resources, and provide feedback on written assignments.
- Creative Writing: Large language models can be used to assist in creative writing tasks, such as generating poetry, writing prompts, and story ideas.
- News and Media: Large language models can be used to generate news articles, summaries, and headlines, as well as analyze and predict trends in the news.
(This list is actually generated by ChatGPT 🙂
Comments are closed.